Кодирование и декодирование информации: что это такое
Рассмотрим детальнее, что такое кодирование сообщений, а также декодирование информации.
Для передачи информации люди используют естественные языки.
В повседневной жизни мы общаемся с помощью неформальной речи, а в деловой сфере используем формальный язык.
Сегодня для передачи и отображения информации мы используем вычислительную технику, которая «не понимает» наш язык без специальных операций – кодирования и декодирования.
Рассмотрим эти понятия детальнее, а также все виды и наглядные примеры кодирования/декодирования.
Cодержание:
Базовые понятия
Прежде чем разобраться с основами процедуры кодирования, следует ознакомиться с несколькими простейшими понятиями.
Код – это набор любых символов или других визуальных обозначений информации, который образует представление данных. В компьютерной технике под кодом подразумевают отдельную систему знаков, которые используют для обработки, передачи и хранения сообщений и файлов.Кодирование – это процесс преобразования текстовой информации в код. Кодов существует огромное количество. Каждый из них отличается своим алгоритмом работы и алфавитом.
К примеру, компьютер, смартфон, ноутбук и любые другие компьютерные устройства работают с двоичным кодом.
Двоичный код использует алфавит, который состоит из двух символов – «0» и «1».
Декодирование – это процедура обратная к кодированию. Декодировщик обратно превращает код в понятную для человека форму представления данных. Среди известных примеров постоянной работы с декодированием можно отметить азбуку Морзе: для «прочтения» сообщения нужно сначала преобразовать полученный код в слова.
В компьютерной технике кодирование происходит, когда пользователь вводит любую информацию в систему – создает файлы, печатает текст и так далее.
Для понимания обычных букв кириллицы или латиницы они превращаются в набор нолей и единиц.
Чтобы отобразиться на экране компьютера, система проводит декодирование числовой последовательности и выводит результат на экран.
Все эти действия выполняются за тысячные доли секунды.
к содержанию ↑История развития кодирования
Телеграф Шаппа
Первым техническим средством кодирования данных был созданный в 1792 году телеграф Шаппа.
Устройство передавало оптическую информацию в простейшем виде с помощью специальной таблицы кодов, в которой каждой букве латинского алфавита соответствовала одна фигура.
В результате, телеграф мог отобразить и передать набор фигур.
Скорость передачи таких сообщений составляла всего два слова в минуту.
Технология такого обмена сообщениями была актуальна больше ста лет после создания телеграфа Шаппа.
Телеграф Морзе
Созданный в 1837 году телеграф Морзе стал революционном устройством кодирования/декодирования информации.
Принцип кодирования заключался в преобразовании любого сообщения в три символа алфавита:
- Длинный сигнал – тире;
- Короткий сигнал – точка;
- Нет сигнала – пауза.
Подобная связь используется по сей день в мореходной сфере для мгновенной передачи сообщений между суднами.
Радиоприёмник
В 1899 году А. Попов создал первый в мире беспроводной телеграф или радиоприемник.
Принцип его работы заключался в кодировании электрических сигналов азбукой Морзе и её дальнейшей передаче на длительные расстояния.
Позже был изобретен телеграф Бодо, который решал проблему неравномерности кода и сложность декодирования.
Следующий этап в развитии кодирования – это создание вычислительных машин и их работа с бинарной системой исчисления.
к содержанию ↑Современные способы кодирования данных
Для перевода информации в код могут быть использованы разные способы и алгоритмы кодирования.
Использование каждого из методов зависит от среды, цели и условий создания кода.
С разными алгоритмами кодирования мы сталкиваемся в повседневной жизни:
- Для записи разговорной речи в режиме реального времени используется стенография;
- Для написания и отправки письма жителю другой страны используем язык получателя;
- Для набора русского текста на англоязычной клавиатуре используем транслит. К примеру, «Привет»>«Privet» и так далее.
Двоичное кодирование и другие числовые системы
Самый простой и распространенный способ кодирования – это представление информации в двоичном (бинарном) коде.
С его помощью работают все компьютеры и вычислительные системы.
Компьютер может выполнять сверхбыстрые вычисления с помощью только двух условий – наличия тока и его напряжение.
С помощью единиц передается высокое напряжение, а с помощью нолей – низкое.
Далее полученная последовательность считывается центральным процессором, обрабатывается, а затем снова преобразуется в читаемый нам вид и выводится на экран.
Для перевода привычных нам слов, цифр и символов в десятичное представление следует использовать специальные таблицы конверсии.
На рисунке ниже изображена таблица для цифровой и символьной раскладки, а также для букв латиницы.
К примеру, в результате перевода фразы «Hello, how are you?» получим последовательность «10010001000101100110010011001001111010110001000001001000100111110101110100001000001101001010001010100000101100110011111010101».
Чтобы выполнить декодирование информации, необходимо разделить бинарный код на части, каждая из которых равна семи ячейкам:
- 1001000 – символ «H»
- 1000101 – символ «E»
- 1001100 – символ «L»
- 1001100 – символ «L»
- 1001111 – символ «O»
- 0101100 – символ «,» и так далее, пока вся последовательность не будет декодирована.
Запятые, точки, другие пунктуационные символы и пробел тоже нужно учитывать при кодировании/декодировании информации.
Также, в теории кодирования можно встретить не только двоичную систему, но и троичную, четвертую, пятую, шестую…шестнадцатеричную и другие системы.
Шестнадцатеричная система исчисления используется в языках программирования низкого уровня.
Таким образом, удаётся добиться более быстрого выполнения кода центральным процессором. Примером такого языка является машинный код ассемблер.
Создание программ на языке низкого уровня является самым сложным и непрактичным, поэтому на практике используют компиляторы – утилиты, которые преобразовывают языки высокого уровня в низкий.
Так шестнадцатеричная система декодируется в двоичную.
Рис.3 – пример декодирования зыков программирования разных уровней
Также, шестнадцатеричная система используется в создании программной документации, так намного проще записывать байты.
Для обозначения одного байта требуется только две шестнадцатеричные цифры, а не восемь, как в двоичной системе.
В повседневной жизни мы используем десятичную систему исчисления, алфавит которой представлен в виде чисел от 0 до 9.
Онлайн-кодировщики
Для быстрого преобразования любого текста в набор символов бинарной или других систем исчисления удобнее использовать автоматические кодировщики.
Также, они могут декодировать текст, самостоятельно определяя, какую систему использовал пользователь для кодировки.
Популярным сервисом для создания или расшифровки двоичного кода является DecodeIT .
Ресурс показывает высокую точность преобразования в обе стороны и отличается очень простым пользовательским интерфейсом.
Рис.4 — Сервис DecodeIT
к содержанию ↑Кодирование символов
Кодирование символов – это еще одна важная часть работы любого компьютерного устройства. От вышеописанных числовых систем она отличается тем, что кодирование происходит уже на этапе работы программы с определенным текстом, сообщением и другим видом данных.
Для кодирования символов используются различные стандарты, среди которых Юникод, ASCII, UTF-8 и другие.
Зачем нужна кодировка символов?
Любые символы на экране компьютера или смартфона отображаются за счет двух вещей:
1 Векторного представления;
2 Предустановленных знаков и их кода.
Знаки – это шрифты, которые поддерживаются устройством. В ОС Windows они находятся в окне Панель управления (директория «Шрифты»).
С помощью этой папки вы можете добавлять или удалять существующие представления символов.
С помощью программного кода выбирается нужное векторное направление символа и его изображение из папки «Шрифты».
Таким образом, на экране появляется буква и текст.
За установку шрифтов отвечает операционная система вашего компьютера, а за кодировку текста – программы, в которых вы набираете или просматриваете текстовые данные.
Любая программа, к примеру стандартный Блокнот, в процессе открытия считывает кодировку каждого знака, производит декодирование данных и выводит информацию для просмотра или дальнейшего редактирования пользователем.
Разбирая код, приложение обрабатывает кодировку знака и ищет его соответствие в поддерживаемом для этого же документа шрифте.
Если соответствие не найдено, вместо текста вы увидите набор непонятных символов.
Рис.5 – пример ошибки кодирования символов в Блокноте Windows
Чтобы символы кириллицы и латиницы открывались без проблем в большинстве программ, было предложено ввести стандарты кодирования.
Один из наиболее популярных – это Юникод (или Unicode).
Он поддерживается практически всеми существующими шрифтами и программным обеспечением.
Также, широко используются технологии UTF-8, ASCII.
Если в программе текст отображается в нечитабельной форме, пользователь может самостоятельно его декодировать.
Для этого достаточно зайти в настройки текстового редактора и сохранить файл с кодировкой Юникод или другими популярными форматами кодирования.
Затем откройте файл заново, текст должен отображаться в нормальном режиме.
Рис.6 – декодирование текста в редакторе
к содержанию ↑Шифрование
Часто возникает необходимость не только закодировать информацию, но и скрыть её содержимое от посторонних.
Для таких целей используется шифрование.
Простыми словами, шифрование – это кодирование информации, но не с целью её корректного представления на экране компьютера, а с целью сокрытия данных от тех, кому не положено получать доступ к шифрованной информации.
Алфавит шифрования состоит из двух элементов:
Алгоритм – уникальная последовательность математических действий с двоичными числами;
Ключ – бинарная последовательность, которая добавляется к шифруемому сообщению.
Дешифрование – это обратный процесс к защитному кодированию, который подразумевает превращение данных в первоначальный вид с помощью известного ключа.
Криптография – это наука о шифровании данных. Всего различают два раздела криптографии:
- Симметричная – в таких криптосистемах кодирования для шифрования и дешифрования используют один и тот же ключ. Недостаток системы – низкая стойкость ко взлому;
- Ассиметричная – для шифрования используются закрытый и открытый ключ. Таким образом, посторонний человек не сможет расшифровать (декодировать) сообщение, даже если алгоритм известен.
Где используется криптография?
Кодирование информации с целью шифрования используется уже более трех тысяч лет.
Истории известны первые попытки шифрованной передачи сообщений между известными полководцами царями и просто высокопоставленными людьми.
Сегодня без криптографии невозможно существование всей банковской системы, ведь каждая карта, каждая авторизация в онлайн-банкинге требует наличия защищенного соединения, при котором злоумышленник не сможет похитить ваши деньги или подобрать пароль.
Также, шифрованное кодирование используется в обычных социальных сетях, мессенджерах.
К примеру, Telegram – мессенджер, главной особенностью которого является кодирование сообщений пользователей таким образом, чтобы никто посторонний не смог взломать переписку.
Также, алгоритмы шифрования встроены во все операционные системы, облачные хранилища.
Они нужны для защиты ваших личных данных.
Рис.7 – принцип работы защищенного соединения
к содержанию ↑Стеганография
Стеганография – это еще один способ кодирования информации.
Он схож с упомянутой выше криптографией, но если основной целью криптографии является защита секретной информации, то стеганография отвечает за сокрытие самого факта о том, что существуют какие-либо защищаемые данные.
Процедура стенографического кодирования подразумевает встраивание сообщения в картинки, музыкальные файлы, видео и так далее.
Алфавитом такого кодирования является область пикселей изображения.
Каждая буква секретного сообщения кодируется в бинарную форму, затем она заменяет один из пикселей.
Таким образом, можно закодировать даже большие сообщения без какого-либо визуального изменения фотографии, так как на современных гаджетах не видны отдельные пиксели картинки.
Аналогичным образом происходит кодирование звука в музыку, каждой частоте присваивается определенная буква.
Декодировать стенографическую информацию можно только с помощью специальных утилит, которые и зашифровали сообщение или путем взлома.
Достаточно сопоставить картинку до и после встраивания секретного текста, количество пикселей будет отличаться.
Затем используется специальное ПО для перебора и расшифровки каждого пикселя и воссоздания сообщения.
к содержанию ↑Итог
Кодирование информации используется сотни лет для удобной передачи данных между устройствами.
С развитием технологий и переносом банковской сферы в техническую среду появилась необходимость в использовании алгоритмов кодирования, которые бы шифровали информацию, сохраняя её от несанкционированного доступа.
Сегодня без технологий кодирования данных невозможна работа ни одного компьютера, смартфона, сайта или банковского счета.
Тематические видеоролики:
Кодирование информации. Стандарты кодирования текста
В информатике большое число информационных процессов проходит с использованием кодирования данных. Поэтому понимание данного процесса очень важно при постижении азов этой науки. Под кодированием информации понимают процесс преобразования символов записанных на разных естественных языках (русский язык, английский язык и т.д.) в цифровое обозначение.
Это означает, что при кодировании текста каждому символу присваивается определенное значение в виде нулей и единиц – байта.
Зачем кодировать информацию?
Во-первых, необходимо ответить на вопрос для чего кодировать информацию? Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид.
Стандарты кодирования текста
Чтобы все компьютеры могли однозначно понимать тот или иной текст, необходимо использовать общепринятые стандарты кодирования текста
ASCII
Самым первым компьютерным стандартом кодирования символов стал ASCII (полное название — American Standart Code for Information Interchange). Для кодирования любого символа в нём использовали всего 7 бит. Как вы помните, что закодировать при помощи 7 бит можно лишь 27 символов или 128 символов. Этого достаточно, чтобы закодировать заглавные и прописные буквы латинского алфавита, арабские цифры, знаки препинания, а так же определенный набор специальных символов, к примеру, знак доллара — «$». Однако, чтобы закодировать символы алфавитов других народов (в том числе и символов русского алфавита) пришлось дополнять код до 8 бит (28=256 символов). При этом, для каждого языка использовалась свой отдельная кодировка.
UNICODE
Нужно было спасать положение в плане совместимости таблиц кодировки. Поэтому, со временем были разработаны новые обновлённые стандарты. В настоящее время наиболее популярной является кодировка под названием UNICODE. В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.
Стандарты кодирования графических данных
Чтобы закодировать изображение требуется гораздо больше байт, чем для кодирования символов. Большинство созданных и обработанных изображений, хранящихся в памяти компьютера, разделяют на две основные группы:
- изображения растровой графики;
- изображения векторной графики.
Растровая графика
В растровой графике изображение представлено набором цветных точек. Такие точки называют пикселями (pixel). При увеличении изображения такие точки превращаются в квадратики.
Для кодирования чёрно-белого изображения каждый пиксель кодируется одним битом. К примеру, чёрный цвет — 0, а белый — 1)
Наше прошлое изображение можно закодировать так:
При кодировании нецветных изображений чаще всего применяют палитру из 256 оттенков серого, начиная от белого и заканчивая чёрным. Поэтому для кодирования такой градации достаточно одного байта (28=256).
В кодирования цветных изображений применяют несколько цветовых схем.
На практике, чаще применяют цветовую модель RGB, где соответственно используется три основных цвета: красный, зелёный и синий. Остальные цветовые оттенки получаются при смешивании этих основных цветов.
Таким образом, для кодирования модели из трёх цветов в 256 тонов, получается свыше 16,5 миллионов разных цветовых оттенков. То есть для кодирования применяют 3⋅8=24 бита, что соответствует 3 байтам.
Естественно, что можно использовать минимальное количество бит для кодирования цветных изображений, но тогда может быть образовано и меньшее количество цветовых тонов, в связи, с чем качество изображения существенно понизится.
Чтобы определить размер изображения нужно умножить количество пикселей в ширину на длину количество пикселей и ещё раз умножить на размер самого пикселя в байтах.
I=a*b*i
Где
- а — количество пикселей в ширину;
- b — количество пикселей в длину;
- I – размер одного пикселя в байтах.
К примеру, цветное изображение размером 800⋅600 пикселей, занимает 60000 байт.
Векторная графика
Объекты векторной графики кодируются совершенно по-другому. Здесь изображение состоит из линий, которые могут иметь свои коэффициенты кривизны.
Стандарты кодирования звука
Звуки, которые слышит человек, представляют собой колебания воздуха. Звуковые колебания – это процесс распространения волн.
Звук имеет две основные характеристики:
- амплитуда колебаний – определяет громкость звука;
- частота колебания — определяет тональность звука.
Звук можно преобразовать в электрический сигнал, с помощью микрофона. Звук кодируется с определенным, заранее заданным интервалом времени. В этом случае измеряется размер электрического сигнала и присваивается бинарная величина. Чем чаще делают данные измерения, тем выше качество звука.
Компакт-диск объемом 700 Мб, вмещает порядка 80 минут звука CD-качества.
Стандарты кодирования видео
Как вы знаете, видеоряд состоит из быстро меняющихся фрагментов. Смена кадров происходит со скоростью в интервале 24-60 кадров в секунду.
Размер видеоряда в байтах определяется размером кадра (количеством пикселей на экран по высоте и ширине), количеством используемых цветов, а также количеством кадров в секунду. Но наряду с этим может присутствовать ещё и звуковая дорожка.
Глоссарий по информатике Система счисления
Что такое кодирование информации и ее обработка?
В мире идет постоянный обмен потоками информации. Источниками могут быть люди, технические устройства, различные вещи, объекты неживой и живой природы. Получать сведения может как один объект, так и несколько.
 Для более качественного обмена данными одновременно осуществляется кодирование и обработка информации на стороне передатчика (подготовка данных и преобразование их в форму, удобную для трансляции, обработки и хранения), пересылка и декодирование на стороне приемника (преобразование кодированных данных в исходную форму). Это взаимосвязанные задачи: источник и приемник должны обладать сходными алгоритмами обработки сведений, иначе процесс кодирования-декодирования будет невозможен. Кодирование и обработка графической и мультимедийной информации обычно реализуются на основе вычислительной техники.
Для более качественного обмена данными одновременно осуществляется кодирование и обработка информации на стороне передатчика (подготовка данных и преобразование их в форму, удобную для трансляции, обработки и хранения), пересылка и декодирование на стороне приемника (преобразование кодированных данных в исходную форму). Это взаимосвязанные задачи: источник и приемник должны обладать сходными алгоритмами обработки сведений, иначе процесс кодирования-декодирования будет невозможен. Кодирование и обработка графической и мультимедийной информации обычно реализуются на основе вычислительной техники.
Кодирование информации на компьютере
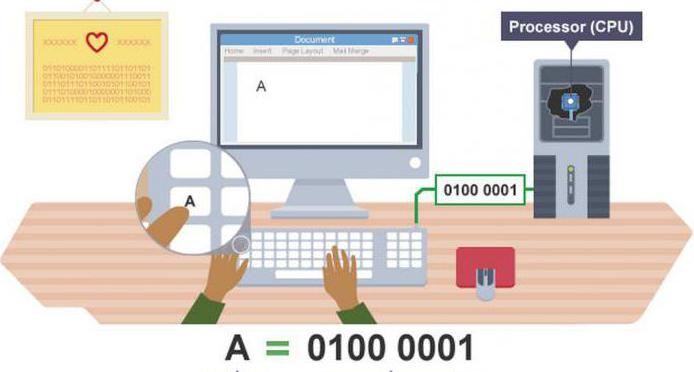
Есть много способов обработки данных (тексты, числа, графика, видео, звук) с помощью компьютера. Вся информация, обрабатываемая компьютером, представлена в двоичном коде — с помощью цифр 1 и 0, называемых битами. Технически этот способ реализуется очень просто: 1 — электрический сигнал присутствует, 0 — отсутствует. С точки зрения человека, такие коды неудобны для восприятия — длинные строчки нулей и единиц, представляющие собой кодированные символы, очень сложно сходу расшифровать. Зато такой формат записи сразу наглядно показывает, что такое кодирование информации. Например, число 8 в двоичном восьмиразрядном виде выглядит как следующая последовательность бит: 000001000. Но то, что сложно человеку, просто компьютеру. Электронике проще обработать множество простых элементов, чем небольшое количество сложных.
Кодирование текстов
Когда мы нажимаем кнопку на клавиатуре, компьютер получает определенный код нажатой кнопки, ищет его в стандартной таблице символов ASCII (американский код для обмена информацией), «понимает» какая кнопка нажата и передает этот код для дальнейшей обработки (например, для отображения символа на мониторе). Для хранения символьного кода в двоичном виде используется 8 разрядов, поэтому максимальное число комбинаций равняется 256. Первые 128 символов используется под управляющие символы, цифры и латинские буквы. Вторая половина предназначается для национальных символов и псевдографики.
Кодирование текстов
Легче будет понять, что такое кодирование информации, на примере. Рассмотрим коды английского символа «С» и русской буквы «С». Заметим, что взяты символы заглавные, и их коды отличаются от строчных. Английский символ будет выглядеть как 01000010, а русский — 11010001. То, что для человека на экране монитора выглядит одинаково, компьютер воспринимает совершенно по-разному. Необходимо также обратить внимание на то, что коды первых 128 символов остаются неизменны, а начиная от 129 и далее одному двоичному коду могут соответствовать различные буквы в зависимости от используемой кодовой таблицы. К примеру, десятичный код 194 может соответствовать в КОИ8 букве «б», в СР1251 — «В», в ISO — «Т», а в кодировках СР866 и Мас вообще этому коду не соответствует ни один символ. Поэтому, когда при открытии текста мы вместо русских слов видим буквенную-символьную абракадабру, это означает, что такое кодирование информации нам не подходит и нужно выбрать другой конвертор символов.
Кодирование чисел
В двоичной системе исчисления берутся всего два варианта значения — 0 и 1. Все основные операции с двоичными числами использует наука под названием двоичная арифметика. Эти действия имеют свои особенности. Возьмем, к примеру, число 45, набранное на клавиатуре. Каждая цифра имеет свой восьмиразрядный код в кодовой таблице ASCII, поэтому число занимает два байта (16 бит): 5 — 01010011, 4 — 01000011 . Для того чтобы использовать это число в вычислениях, оно переводится по специальным алгоритмам в двоичную систему исчисления в виде восьмиразрядного двоичного числа: 45 — 00101101.

Кодирование и обработка графической информации
В 50-х годах на компьютерах, которые чаще всего использовались в научных и военных целях, впервые реализовали графическое отображение данных. Сегодня визуализация информации, получаемой от компьютера, является обычным и привычным для любого человека явлением, а в те времена это произвело необычайный переворот в работе с техникой. Возможно, сказалось влияние человеческой психики: наглядно представленная информация лучше усваивается и воспринимается. Большой рывок в развитии визуализации данных произошел в 80-х годах, когда кодирование и обработка графической информации получили мощное развитие.

Аналоговое и дискретное представление графики
Графическая информация бывает двух видов: аналоговая (живописное полотно с непрерывно изменяющимся цветом) и дискретная (картинка, состоящая из множества точек разного цвета). Для удобства работы с изображениями на компьютере их подвергают обработке — пространственной дискретизации, при которой каждому элементу назначается конкретное значение цвета в виде индивидуального кода. Кодирование и обработка графической информации похожи на работу с мозаикой, состоящей из большого количества мелких фрагментов. Причем качество кодирования зависит от размеров точек (чем меньше размер элемента — точек будет большее количество на единицу площади, — тем выше качество) и размера палитры используемых цветов (чем больше цветовых состояний может принимать каждая точка, соответственно, неся больше информации, тем лучше качество).
Создание и хранение графики
Есть несколько основных форматов изображений — векторный, фрактальный и растровый. Отдельно рассматривается сочетание растровой и векторной — широко распространенная в наше время мультимедийная 3D-графика представляющая собой приемы и методы построения трехмерных объектов в виртуальном пространстве. Кодирование и обработка графической и мультимедийной информации различна для каждого формата изображений.

Растровое изображение
Суть этого графического формата в том, что рисунок разбивается на мелкие разноцветные точки (пиксели). Верхняя левая точка контрольная. Кодирование графической информации всегда начинается с левого угла изображения построчно, каждый пиксель получает код цвета. Объем растровой картинки можно вычислить умножением количества точек на информационный объем каждого из них (который зависит от количества вариантов цвета). Чем выше разрешающая способность монитора, тем больше количество строк растра и точек в каждой строке, соответственно, выше качество изображения. Для обработки графических данных растрового типа можно использовать двоичный код, так как яркость каждой точки и координаты ее расположения можно представить в виде целых чисел.
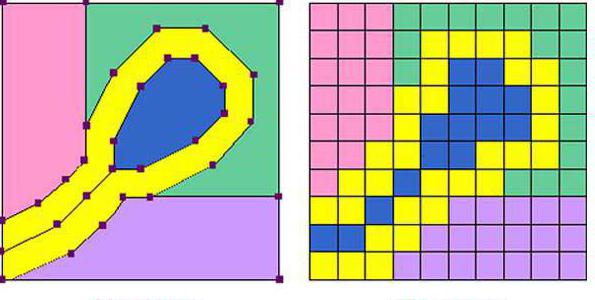
Векторное изображение
Кодирование графической и мультимедийной информации векторного типа сводится к тому, что графический объект представляется в виде элементарных отрезков и дуг. Свойствами линии, являющейся базовым объектом, являются форма (прямая или кривая), цвет, толщина, начертание (пунктир или сплошная линия). Те линии, которые являются замкнутыми, обладают еще одним свойством — заполнение другими объектами или цветом. Положение объекта определяется точками начала и конца линии и радиусом искривления дуги. Объем графической информации векторного формата значительно меньше растрового, но требует специальных программ для просмотра графики этого типа. Существуют также программы — векторизаторы, преобразующие растровые изображения в векторные.
Фрактальная графика
Этот тип графики, как и векторный, основан на математических расчетах, но ее базовой составляющей является сама формула. В памяти компьютера нет необходимости хранить никаких изображений или объектов, сама картинка рисуется только по формуле. Графикой такого типа удобно визуализировать не только простые регулярные структуры, но и сложные иллюстрации, имитирующие, например, ландшафты в играх или эмуляторах.
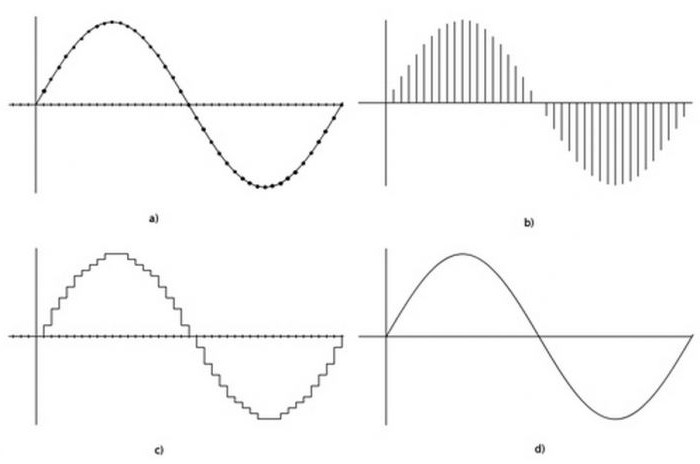
Звуковые волны
Что такое кодирование информации, еще можно продемонстрировать на примере работы со звуком. Мы знаем, что наш мир переполнен звуками. С древних времен люди разобрались, как рождаются звуки — волны сжатого и разреженного воздуха, воздействующие на барабанные перепонки уха. Человек может воспринимать волны с частотой от 16 Гц до 20 кГц (1 Герц — одно колебание в секунду). Все волны, частоты колебаний которых попадают в этот диапазон, называются звуковыми.
Свойства звука
Характеристиками звука являются тон, тембр (окраска звука, зависящая от формы колебаний), высота (частота, которая определяется частотой колебаний в секунду) и громкость, зависящая от интенсивности колебаний. Любой реальный звук состоит из смеси гармонических колебаний с фиксированным набором частот. Колебание с самой низкой частотой называют основным тоном, остальные — обертонами. Особую окраску звуку придает тембр — различное количество обертонов, присущее именно этому звуку. Именно по тембру мы можем узнавать голоса близких людей, отличать звучание музыкальных инструментов.
Программы для работы со звуком
Условно программы по функционалу можно разделить на несколько видов: служебные программы и драйверы для звуковых плат, работающие с ними на низком уровне, аудио редакторы, которые производят различные операции со звуковыми файлами и применяют к ним различные эффекты, программные синтезаторы и преобразователи аналого-цифровые (АЦП) и цифро-аналоговые (ЦАП).
Кодирование звука
Кодирование мультимедийной информации состоит в преобразовании аналоговой природы звука в дискретную для более удобной ее обработки. АЦП получает на входе аналоговый сигнал, измеряет его амплитуду в определенные промежутки времени и выдает на выходе цифровую последовательность с данными об изменениях амплитуды. Никаких физических преобразований не происходит.
Выходной сигнал является дискретным, поэтому, чем чаще частота измерения амплитуды (сэмпл), тем точнее выходной сигнал соответствует входному, тем лучше проходит кодирование и обработка мультимедийной информации. Сэмплом также принято называть упорядоченную последовательность цифровых данных, полученных через АЦП. Сам процесс при этом называется сэмплированием, по-русски — дискретизацией.
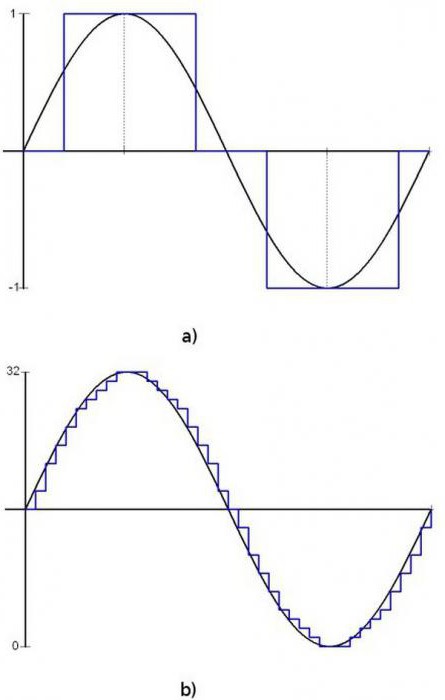
Обратное преобразование происходит при помощи ЦАП: на основании поступающих на вход цифровых данных в определенные моменты времени происходит генерация электрического сигнала необходимой амплитуды.
Параметры дискретизации
Основными параметрами сэплирования являются не только частота измерения, но и разрядность — точность измерения изменения амплитуды за каждый сэмпл. Чем точнее передается при оцифровке значение амплитуды сигнала в каждую единицу времени, тем выше качество сигнала после АЦП, тем выше достоверность восстановление волны при обратном преобразовании.
Что такое кодирование и декодирование? Примеры. Способы кодирования и декодирования информации числовой, текстовой и графической
Эксплуатация электронно-вычислительной техники для обработки данных стала важным этапом в процессе совершенствования систем управления и планирования. Но такой метод сбора и обработки информации несколько отличается от привычного, поэтому требует преобразования в систему символов, понятных компьютеру.
Что такое кодирование информации?
Кодирование данных – это обязательный этап в процессе сбора и обработки информации.
Как правило, под кодом подразумевают сочетание знаков, которое соответствует передаваемым данным или некоторым их качественным характеристикам. А кодирование – это процесс составления зашифрованной комбинации в виде списка сокращений или специальных символов, которые полностью передают изначальный смысл послания. Кодирование еще иногда называют шифрованием, но стоит знать, что последняя процедура предполагает защиту данных от взлома и прочтения третьими лицами.

Цель кодирования заключается в представлении сведений в удобном и лаконичном формате для упрощения их передачи и обработки на вычислительных устройствах. Компьютеры оперируют лишь информацией определенной формы, поэтому так важно не забывать об этом во избежание проблем. Принципиальная схема обработки данных включает в себя поиск, сортировку и упорядочивание, а кодирование в ней встречается на этапе ввода сведений в виде кода.
Что такое декодирование информации?
Вопрос о том, что такое кодирование и декодирование, может возникнуть у пользователя ПК по различным причинам, но в любом случае важно донести корректную информацию, которая позволит юзеру успешно продвигаться в потоке информационных технологий дальше. Как вы понимаете, после процесса обработки данных получается выходной код. Если такой фрагмент расшифровать, то образуется исходная информация. То есть декодирование – это процесс, обратный шифрованию.
Если во время кодирования данные приобретают вид символьных сигналов, которые полностью соответствуют передаваемому объекту, то при декодировании из кода изымается передаваемая информация или некоторые ее характеристики.
Получателей закодированных сообщений может быть несколько, но очень важно, чтобы сведения попали в руки именно к ним и не были раскрыты раньше третьими лицами. Поэтому стоит изучить процессы кодирования и декодирования информации. Именно они помогают обмениваться конфиденциальными сведениями между группой собеседников.
Кодирование и декодирование текстовой информации
При нажатии на клавиатурную клавишу компьютер получает сигнал в виде двоичного числа, расшифровку которого можно найти в кодовой таблице – внутреннем представлении знаков в ПК. Стандартом во всем мире считают таблицу ASCII.

Однако мало знать, что такое кодирование и декодирование, необходимо еще понимать, как располагаются данные в компьютере. К примеру, для хранения одного символа двоичного кода электронно-вычислительная машина выделяет 1 байт, то есть 8 бит. Эта ячейка может принимать только два значения: 0 и 1. Получается, что один байт позволяет зашифровать 256 разных символов, ведь именно такое количество комбинаций можно составить. Эти сочетания и являются ключевой частью таблицы ASCII. К примеру, буква S кодируется как 01010011. Когда вы нажимаете ее на клавиатуре, происходит кодирование и декодирование данных, и мы получаем ожидаемый результат на экране.
Половина таблицы стандартов ASCII содержит коды цифр, управляющих символов и латинских букв. Другая ее часть заполняется национальными знаками, псевдографическими знаками и символами, которые не имеют отношения к математике. Совершенно ясно, что в различных странах эта часть таблицы будет отличаться. Цифры при вводе также преобразовываются в двоичную систему вычисления согласно стандартной сводке.

Кодирование чисел
В двоичной системе счисления, которую активно используют компьютеры, встречаются лишь две цифры – 0 и 1.
Действия с образовывающимися числами двоичной системы изучает двоичная арифметика. Большинство законов основных математических действий для таких цифр остаются актуальными.
Примеры кодирования и декодирования чисел
Предлагаем рассмотреть 2 способа кодировки числа 45. Если эта цифра встречается в пределах текстового фрагмента, то каждая ее составляющая будет закодирована, согласно таблице стандартов ASCII, 8 битами. Четверка превратится в 01000011, а пятерка – в 01010011.
Если число 45 используется для вычислений, то будет задействована специальная методика преобразования в восьмиразрядный двоичный код 001011012, для хранения которого нужен будет всего лишь 1 байт.

Кодирование графической информации
Увеличив монохромное изображение с помощью лупы, вы увидите, что оно состоит из огромного количества мелких точек, формирующих полноценный узор. Индивидуальные качества каждой картинки и линейные координаты любой точки можно отобразить в форме чисел. Поэтому растровое кодирование базируется на двоичном коде, приспособленном для отображения графической информации.
Черно-белые картинки – это комбинации точек с различными оттенками серого цвета, то есть яркость любой точки изображения определяют восьмиразрядные двоичные числа. Принцип разложения произвольного градиента на базовые составляющие – это основа такого процесса, как кодирование графической информации. Декодирование картинок происходит таким же путем, но в обратном направлении.
При разложении используются три основных цвета: зеленый, красный и синий, ведь любой естественный оттенок можно получить, комбинируя эти градиенты. Такую систему кодирования принято называть RGB. В случае использования двадцати четырех двоичных разрядов для шифрования графического изображения режим преобразования называют полноцветным.
Все основные цвета сопоставляются с оттенками, которые дополняют базовую точку, делая ее белой. Дополнительный цвет – это градиент, образованный суммой прочих основных тонов. Выделяют желтый, пурпурный и голубой дополнительные цвета.
Подобный метод кодирования точек изображений применяется и в полиграфической отрасли. Только здесь принято задействовать четвертый цвет – черный. По этой причине полиграфическую систему преобразования обозначают аббревиатурой CMYK. Эта система для представления изображений использует целых тридцать два двоичных разряда.

Способы кодирования и декодирования информации предполагают использование различных технологий, в зависимости от типа вводимых данных. К примеру, метод шифрования графических изображений шестнадцатиразрядными двоичными кодами называется High Color. Эта технология дает возможность передавать на экран целых двести пятьдесят шесть оттенков. Уменьшая количество задействованных двоичных разрядов, применяемых для шифрования точек графического изображения, вы автоматически уменьшаете объем, необходимый для временного хранения информации. Такой метод кодирования данных принято называть индексным.
Кодирование звуковой информации
Теперь, когда мы рассмотрели, что такое кодирование и декодирование, и методы, лежащие в основе этого процесса, стоит остановиться на таком вопросе, как кодирование звуковых данных.
Звуковую информацию можно представить в виде элементарных единиц и пауз между каждой их парой. Каждый сигнал преобразовывается и сохраняется в памяти компьютера. Звуки выводятся с помощью синтезатора речи, который используется хранящиеся в памяти ПК зашифрованные комбинации.
Что касается человеческой речи, то ее гораздо сложнее закодировать, ведь она отличается многообразием оттенков, и компьютеру приходится сравнивать каждое словосочетание с эталоном, предварительно занесенным в его память. Распознавание произойдет лишь в случае, когда сказанное слово будет найдено в словаре.
Кодирование информации в двоичном коде
Существуют различные методики реализации такой процедуры, как кодирование числовой, текстовой и графической информации. Декодирование данных обычно происходит по обратной технологии.
При кодировании чисел даже учитывается цель, с которой цифра была введена в систему: для арифметических вычислений или просто для вывода. Все данные, кодируемые в двоичной системе, шифруются с помощью единиц и ноликов. Эти символы еще называют битами. Этот метод кодировки является наиболее популярным, ведь его легче всего организовать в технологическом плане: присутствие сигнала – 1, отсутствие – 0. У двоичного шифрования есть лишь один недостаток – это длина комбинаций из символов. Но с технической точки зрения легче орудовать кучей простых, однотипных компонентов, чем малым числом более сложных.
Преимущества двоичного кодирования
- Такая форма представления информации подходит для различных ее видов.
- При передаче данных не возникает никаких ошибок.
- ПК намного легче обрабатывать данные, закодированные таким способом.
- Требуются устройства с двумя состояниями.
Недостатки двоичного кодирования
- Большая длина кодов, которая несколько замедляет их обработку.
- Сложность восприятия двоичных комбинаций человеком без специального образования или подготовки.

Заключение
Ознакомившись с этой статьей, вы смогли узнать, что такое кодирование и декодирование и для чего его используют. Можно сделать вывод, что используемые методики преобразования данных полностью зависят от типа информации. Это может быть не только текст, а еще и числа, изображения и звук.
Кодирование различной информации позволяет унифицировать форму ее представления, то есть сделать однотипной, что значительно ускоряет процессы обработки и автоматизации данных при дальнейшем использовании.
В электронно-вычислительных машинах чаще всего используют принципы стандартного двоичного кодирования, которое исходную форму представления информации преобразовывает в формат, более удобный для хранения и дальнейшей обработки. При декодировании все процессы происходят в обратном порядке.
Способы кодирования информации
Определение 1
Кодированием информации называют преобразование данных в вид, удобный для обработки и передачи. То есть, по сути, это превращение одной информационной формы в другую. А собственно код — это комбинация символов для обозначения общепринятых и общеизвестных понятий.
Как правило, определённые образы при кодировке (можно сказать шифровании) могут быть выражены определёнными знаками. Набор различных знаков образует некое множество с ограниченным набором элементов. Электронные вычислительные машины способны работать только с информационными данными, заданными в формате чисел. Поэтому информационные данные других видов (к примеру, речь, различные звуки, изображения и так далее) для использования и преобразования компьютерными программами необходимо представить в числовом формате.
В качестве примера можно рассмотреть преобразование в формат набора чисел музыкальных звуков. Для этого необходимо через определённые временные интервалы определять амплитуду звуковых колебаний на некотором наборе частот, выражая в виде числа итоги этих замеров. Далее, используя специальное программное обеспечение, возможно сделать практически любую обработку этих данных. К примеру, соединить звуковую информацию от различных источников.
Аналогично этому, возможно преобразовывать и любые данные, представленные в виде текста. При наборе текста, например, с клавиатуры компьютера, любой символ заменяется некоторым числовым значением, а при выводе сформированного текстового файла на дисплей или принтер, выполняется обратная процедура. То есть набор чисел преобразуется в понятные людям визуальные образы букв.
Замечание 1
Выстроенную связь между числовыми значениями и соответствующими им буквами, можно назвать кодировкой символов.
В компьютерной технике принято использовать не десятичную, а более легко реализуемую электроникой, двоичную систему счисления. То есть, применяются всего две цифры ноль и единица, что соответствует двум устойчивым состояниям базового элемента электроники, триггера. Но ввод и вывод числовой информации осуществляется в привычной обычному человеку десятичной системе счисления, что обеспечивает соответствующее программное обеспечение.
Методы кодирования данных
Одни и те же информационные данные можно выразить (кодировать) в различных форматах. С созданием электронных вычислительных машин появилась потребность кодировать практически все типы информационных данных, с которыми связаны конкретные люди и всё мировое сообщество в целом. Но заниматься проблемой шифрования (кодирования) информации люди начали ещё до изобретения электронных вычислительных машин. Великие изобретения людей, какими являются письменность и математика (и её подраздел, арифметика), по сути и есть методы кодирования человеческой речи и числовых данных.
В абсолютно чистом виде информацию мы нигде не встретим, в любом случае она будет как-то выражена (закодирована). Самым распространённым методом выражения информации является система двоичных кодов. В электронных вычислительных машинах, в роботизированных комплексах, в устройствах числового программного управления (УЧПУ) металлорежущими и другими станками, информационные данные, с которыми оперирует оборудование, представлены в виде набора двоичных чисел.
Кодирование текстовой (символьной) и числовой информации
Главная процедура, выполняемая над каждым элементом текстовых данных, это сопоставление символов. В процедуре сравнения символов основным моментом выступает неповторимость шифра (кода) любого символа и размер данного шифра (кода), а собственно метод кодировки фактически не важен.
Чтобы закодировать какой-либо текст, применяются разнообразные таблицы перекодирования. Главное, чтобы для кодирования и последующего декодирования применялись одни и те же таблицы. Таблица перекодирования должна включать в свой состав формализованный определённым порядком список символов для кодирования, согласно которому выполняется перевод символа в двоичный код, а также обратная процедура.
Самые распространённые формы таблиц это:
- ДКОИ-8,
- ASCII,
- CP1251,
- Unicode.
Длина кода представления символа уже давно сформировалась как 8 бит (1 байт). И именно по этой причине один текстовый символ занимает один байт памяти компьютера. Соответственно, число вариантов (комбинаций) набора нулей и единиц при размере кода 8 бит будет два в восьмой степени, то есть 256. Это означает, одна таблица для перекодирования позволяет кодировать максимум 256 символов. Но если использовать код длиною в два байта, то это число соответственно возрастёт до 65536 символов.
У кодирования чисел и текста есть один общий момент, для возможности сравнения данных такого вида, различные числа (как и в случае символов) обязаны иметь разные коды. Главной отличительной особенностью числовой информации от символьной, является то, что числа кроме процедуры сравнения, подвергаются ещё самым разным арифметическим операциям (вычитание и сложение, умножение и так далее). Для выполнения этих действий в электронных вычислительных машинах служит двоичная позиционная система счисления.
При кодировании текстовой информации каждый символ имеет своё двоичное число (код) от 00000000 до 11111111, что в десятичной системе соответствует числам от 0 до 255.
Замечание 2
Следует учитывать, что для кодирования букв русского алфавита существует пять разных кодовых таблиц (КОИ — 8, СР1251, СР866, Мас, ISO), при этом, если текст вводился с применением одной из таблиц, то он будет неправильно декодироваться при использовании другой таблицы.
Кодирование графической информации
Одним из основных действий при кодировании графики (изображения) можно считать разделение её на отдельные составные части. Этот процесс называется дискретизация. Главными методами отображения графической информации для сохранения и дальнейшей работы с ней на электронной вычислительной машине можно считать растровые и векторные изображения. Векторные изображения – это объекты графики, которые составлены из разных простейших фигур геометрии (обычно это дуги окружности и отрезки прямых). Расположение этих геометрических фигур задаётся координатами точек и длинами радиусов.
История кодирования информации
Необходимость кодирования информации и его история
Люди воспринимают внешнюю среду через свои органы чувств, то есть посредством зрения, слуха, обоняния, осязания, вкуса. Для правильной ориентации в окружающей действительности, человек старается запомнить эти данные, то есть сохранить информацию. Чтобы разрешить какие-то свои проблемы, люди, на основе анализа и обработки имеющейся информации, вырабатывают и принимают нужные решения. При общении с себе подобными, люди получают и отдают информацию. Человечество существует в информационном мире. Но одинаковая информация может иметь различные форматы представления (кодировки). Когда появились компьютеры, то появилась и потребность кодировать все информационные потоки, с которыми сталкиваются как отдельные люди, так и весь мир. Но применять кодирование информации люди стали гораздо раньше. Главные изобретения цивилизации людей, математика и письмо, это по сути системы кодировки числовых и речевых информационных данных. Как правило, нет информации как таковой, она всегда выражена в той или иной форме, то есть закодирована.
Замечание 1
Наиболее распространённым видом представления данных является кодирование в двоичном формате. Оно применяется в электронных вычислительных машинах и многих других устройствах, основой которых являются процессоры.
Люди начали применять шифровки (кодирование) текста с момента появления первых засекреченных данных. Наиболее известны следующие способы кодирования, придуманные на разных ступенях развития общества:
- Криптографический способ или тайнопись – это изменение текста сообщения, которое делает его непонятным для людей, не знающих шифра.
- Азбука Сэмюеля Морзе или телеграфное кодирование, при котором каждый символ представляется набором точек и тире (коротких или длинных электрических импульсов).
- Способ сурдожестов или язык, применяемый плохо слышащими людьми, то есть язык на базе жестикуляций.
Но если рассматривать более подробно исторические этапы кодирования, надо обратиться к истории Древней Греции. В Древней Греции был историк Полибий, живший во втором веке до нашей эры. Он предложил кодировать буквы греческого алфавита различными наборами факелов.
Самым первым способом символьной шифровки считается метод Гая Юлия Цезаря, который жил в первом веке до нашей эры. Он основывается на методе замены букв сообщения, подлежащего шифрованию, на другие, отстоящие в алфавите от шифруемой буквы на определённое число элементов. При этом алфавит может считываться по замкнутому кругу. Например, если взять слово «байт», то при сдвиге на две буквы вперёд получится код «гвлф». Процесс декодирования выполняется в обратном порядке.
В 1791 году учёный Клод Шапп предложил использовать оптический семафор-телеграф. В нём разные положения планки семафора кодировали буквы алфавита.
Рисунок 1. Оптический семафор К Шаппа и его телеграфный алфавит. Автор24 — интернет-биржа студенческих работ
Затем уже в 1832-33 годах русским физиком П.Л. Шиллингом и профессорами Гёттингенского университета Вебером и Гауссом было предложено кодировать буквы движением электромагнитной стрелки. Это был электромагнитный телеграф. И уже затем, как развитие этой идеи, в 1837 году появился наиболее сегодня известный телеграфный аппарат Морзе.
В1861году был разработан международный код для передачи оптических сообщений с помощью двух флажков в руках человека. Изобрёл его морской капитан Фредерик Марьят, используя набор корабельных сигналов.
Рисунок 2. Морская азбука сигнальных флажков. Автор24 — интернет-биржа студенческих работ
Далее, как развитие проводного телеграфа Морзе, был изобретён беспроводной радиотелеграф. Его независимо друг от друга изобрели А.С. Попов в 1895 году, и И. Маркони в 1897 году.
Дальнейшим развитием коммуникаций и кодирования стал беспроволочный телефон и изобретение телевидения в 1935 году. Вскоре появились и электронные вычислительные машины, новые средства кодирования и связи двадцатого века. По сути, с этого началась новейшая эра информационного общества. Но вместе с необходимостью передачи информационных потоков, появилась и потребность сделать невозможным доступ к этой информации посторонних людей. Если вернуться назад в историю, то ещё в 1580 году Френсис Бэкон, так изложил основные необходимые моменты шифрования (кодирования) информации:
- Необходимо, чтобы шифр был достаточно прост в использовании.
- Шифрование должно быть надёжным и трудным для дешифрации посторонними.
- Шифровка должна быть скрытной и не подозрительной.
Замечание 2
Кодирование по принципу Бэкона заключалось в использовании сочетания зашифрованного текстового сообщения с дезинформирующими символами, которыми были нули. То есть, двузначное шифрование применялось гораздо раньше появления электронных вычислительных машин.
В 1948 году Клод Шеннон сформулировал теорию информации, что стало новым импульсом в развитии принципов кодирования. Мысли, приведённые им в работе «Математическая теория связи», стали теоретической базой анализа, транслирования и сохранения информационных данных. Итогом его научной работы стало создание и развитие устойчивых к помехам способов кодирования и возможности простого декодирования информации.
Цели кодирования информации
Основными целями кодирования являются:
- Увеличение скорости передачи данных, что означает большую эффективность коммуникации.
- Преобразование информационных данных в самую удобную для электронных вычислительных машин форму.
- Сокращение избыточной информации ведёт к снижению требований к скорости передачи.
- Уменьшение объёмов памяти для хранения информации.
- Существенное улучшение защиты от помех при трансляции информации.
При кодировании изображений происходит преобразование из аналоговой формы информации в дискретный код. Примером аналогового представления информации может служить картина, написанная художником, а её фотография, распечатанная на струйном принтере, состоит из набора мелких точечных элементов различного цвета, что является примером дискретной информации. По сути, это кодирование аналоговой информации и один из последних этапов истории кодирования.
Что такое кодирование и декодирование информации? Алфавит кодирования :: SYL.ru
Современный мир построен на использовании и передаче информации. Но голосом ведь всем её не донесёшь. Поэтому с давних времён был важен момент кодирования данных, чтобы они могли был прочитаны теми, для кого предназначалось. Постепенно также стало актуальным их шифрование. Необходимо было поместить в сообщение информацию, которая была понятна своим и не раскрыла смысла перед чужими. Обо всём этом мы и поговорим, выясняя, что такое кодирование и декодирование.
Разбираемся с терминологией
 Без этого никак. Когда говорят о закодированном тексте, то это значит, что ему был сопоставлен другой набор символов. Это может быть использовано для увеличения надежности или же по той простой причине, что канал может использовать только ограниченное количество символом. Например, двоичный код, на котором работают современные компьютеры, построен на нулях и единицах.
Без этого никак. Когда говорят о закодированном тексте, то это значит, что ему был сопоставлен другой набор символов. Это может быть использовано для увеличения надежности или же по той простой причине, что канал может использовать только ограниченное количество символом. Например, двоичный код, на котором работают современные компьютеры, построен на нулях и единицах.Информация может быть закодирована в определённые символы и для того, чтобы её сохранить. В качестве примера можно привести результаты анализов, где содержатся показатели организма человека. Но наиболее популярным вопросом является такой: «Что такое кодирование и декодирование в информатике?» Искать ответ на него мы и будем.
О значении
Ранее процесс кодирования и декодирования информации играл вспомогательную роль и не рассматривался как отдельное направление математики. Но с появлением электронно-вычислительных машин ситуация существенно изменилась. Сейчас кодирование является центральным вопросом во время решения широкого спектра практических задач в программировании и поэтому пронизывает все информационные технологии. Так, с его помощью:
- Защищается информация от несанкционированного доступа.
- Обеспечивается помехоустойчивость при передаче по каналам связи данных.
- Представляется информация произвольной природы (графика, текст, числа) в памяти компьютера.
- Сжимается содержимое баз данных.
Об алфавите
 Говоря о том, что такое кодирование и декодирование, сложно обойти вниманием основу всего этого. А именно, алфавит. Выделяют два вида – исходный и кодовый. В первом имеется начальная информация. Под кодовым подразумеваются изменённые данные, которые тем не менее могут при наличии ключа передать нам зашифрованное содержимое. В информатике для этого используется двоичный код, в основу которого положен алфавит, состоящий из нуля и единицы.
Говоря о том, что такое кодирование и декодирование, сложно обойти вниманием основу всего этого. А именно, алфавит. Выделяют два вида – исходный и кодовый. В первом имеется начальная информация. Под кодовым подразумеваются изменённые данные, которые тем не менее могут при наличии ключа передать нам зашифрованное содержимое. В информатике для этого используется двоичный код, в основу которого положен алфавит, состоящий из нуля и единицы.Давайте рассмотрим небольшой пример. Допустим, у нас есть два алфавита (А и Б), что состоят из конечного числа символов. Допустим, они выглядят следующим образом: А = {А0, А1, А2….А33}, Б = {Б0, Б1, Б3…Б34}. Элементы алфавита – это буквы. Тогда как их упорядоченный набор называется словом. У него есть определённая длина. Первая буква слова называется началом (префиксом), тогда как последняя — окончанием (постфиксом). Могут существовать различные правила построения конструкций. Например, одни системы кодирования информации требуют, чтобы был пропуск между словами, вторые обходятся без него. В целом алфавит необходим для построения универсальной системы отображения информации, её хранения, обработки и передачи. При этом предусматривается определённое соответствие между различными сигналами и элементами сообщений, которые в них зашифрованы.
Работа с данными
 Когда информация преобразовывается в первоначальный вид, то происходящий при этом процесс называется декодирующим. Он должен выполняться по отношению к любым данным, что были зашифрованы. При этом используется так называемое обратное отображение (биекция). Давайте рассмотрим ситуацию с двоичной системой. У неё все кодовые слова обладают одинаковой длиной. Поэтому код называют равномерным (блочным). При этом кодирующей функцией выступает определённая подстановка. Можно взять в качестве примера вышеприведенную систему алфавита. Для обозначения определённых последовательностей используется множество элементарных кодов.
Когда информация преобразовывается в первоначальный вид, то происходящий при этом процесс называется декодирующим. Он должен выполняться по отношению к любым данным, что были зашифрованы. При этом используется так называемое обратное отображение (биекция). Давайте рассмотрим ситуацию с двоичной системой. У неё все кодовые слова обладают одинаковой длиной. Поэтому код называют равномерным (блочным). При этом кодирующей функцией выступает определённая подстановка. Можно взять в качестве примера вышеприведенную систему алфавита. Для обозначения определённых последовательностей используется множество элементарных кодов.Допустим, что у нас есть А0 = {А, Б, В, Г} и Б0 = {1, 0}. Каким образом это можно представить компьютеру? А используя вот такую последовательность: А = 00, Б = 01, В = 10, Г = 11. Как видите, каждый символ имеет определённую кодировку. В компьютерную технику заносится справочная информация про алфавит кодирования, и она начинает ждать поступающих сигналов. Приходит нуль, за ним ещё один – ага, значит, это буква А. Если проводить параллели с набором слова в текстовом редакторе, то следует отметить, что будет передана не только одна буква, но и запущена соответствующая реакция на неё. Например, загорится определённая последовательность светодиодов монитора, где отображаются все введённые символы.
Специфика работы
 Говоря про примеры кодирования и декодирования информации, следует отметить, что рассматриваемая система не является взаимно-однозначной. Например, букве А может соответствовать комбинация не только 00, но и 11, 10 или 01. Но при этом следует учитывать, что может быть только что-то одно. То есть за комбинацией закрепляется исключительно только определённый символ. Если схема кодирования подразумевает разделение любого слова на элементарные составляющие, то она называется разделимой. В случаях, когда одна буква не выступает в качестве начала другой, это префиксный подход. Это относится к вопросам программно-аппаратной составляющей. Определённое влияние на кодирование оказывает и архитектура, но из-за большого количества вариантов реализации рассматривать её довольно проблематично.
Говоря про примеры кодирования и декодирования информации, следует отметить, что рассматриваемая система не является взаимно-однозначной. Например, букве А может соответствовать комбинация не только 00, но и 11, 10 или 01. Но при этом следует учитывать, что может быть только что-то одно. То есть за комбинацией закрепляется исключительно только определённый символ. Если схема кодирования подразумевает разделение любого слова на элементарные составляющие, то она называется разделимой. В случаях, когда одна буква не выступает в качестве начала другой, это префиксный подход. Это относится к вопросам программно-аппаратной составляющей. Определённое влияние на кодирование оказывает и архитектура, но из-за большого количества вариантов реализации рассматривать её довольно проблематично.Побуквенное кодирование
Это наиболее простой подход. Если говорить про языки кодирования информации, то, пожалуй, это наиболее популярный вариант. В ограниченном варианте он был рассмотрен выше. Давайте узнаем, как выглядит код без разделителей. Допустим, у нас есть алфавит (исходный), в который помещены все русские буквы. Для кодирования используются десятичные цифры. Здесь А = 1, а Я = 33. Таким образом, последовательность букв АЯЯА можно передать как 133331. Если есть желание сделать алфавит равномерным, то необходимо внести определённые изменения. Так, для первых девяти букв придётся добавить по нулю. И рассмотренный нами пример АЯЯА превращается в 01333301.
Неравномерное кодирование
Рассмотренный ранее вариант считается удобным. Но в определённых случаях более умно сделать ставку на неравномерные коды. Это имеет смысл тогда, когда разные буквы в исходном тексте встречаются с различной частотой. Поэтому более частые символы имеет смысл кодировать короткими обозначениями, а редкие – длинными. Давайте построим бинарное дерево из букв русского алфавита. А на дополнение возьмём спецсимволы. Наиболее часто используются буквы, поэтому начинать мы будем с них: А – 0, Б – 1, В – 10, Г – 11 и так далее. И только после них уже будут использоваться знаки вопроса, процентов, двоеточия и прочие. Хотя, пожалуй, на первое место всё же следует поставить запятые и точки.
Об условии Фано
 Теорема гласит, что любой код (префиксный и равномерный) допускает возможность однозначного кодирования. Допустим, что мы используем рассмотренный ранее пример с 01333301. Начинаем двигаться вправо. 0 ничего нам не даёт. А вот 01 позволяет идентифицировать букву А. Немного изменим начальный код и представим его как 01 333301. Далее выделяем первую Я, вторую и ещё одну А. В результате мы имеем 01 33 33 01. Хотя первоначально код был слитным, но сейчас мы можем с легкостью его декодировать, поскольку знаем, что в нём есть. А именно – А Я Я А. При этом заметьте, что он всегда расшифровывается однозначно, и никаких толкований в рамках принятой системы нет, благодаря чему можно обеспечить высокую достоверность передаваемой информации. Но как работают компьютеры?
Теорема гласит, что любой код (префиксный и равномерный) допускает возможность однозначного кодирования. Допустим, что мы используем рассмотренный ранее пример с 01333301. Начинаем двигаться вправо. 0 ничего нам не даёт. А вот 01 позволяет идентифицировать букву А. Немного изменим начальный код и представим его как 01 333301. Далее выделяем первую Я, вторую и ещё одну А. В результате мы имеем 01 33 33 01. Хотя первоначально код был слитным, но сейчас мы можем с легкостью его декодировать, поскольку знаем, что в нём есть. А именно – А Я Я А. При этом заметьте, что он всегда расшифровывается однозначно, и никаких толкований в рамках принятой системы нет, благодаря чему можно обеспечить высокую достоверность передаваемой информации. Но как работают компьютеры?Функционирование электронно-вычислительных машин
Кодирование и декодирование сигналов компьютерной техники базируется на использовании так называемых низких и высоких сигналов, которым в логическом измерении соответствуют нуль и единица. Что это значит? Допустим, у нас есть микроконтроллер. Если на один его вход поступает низкое напряжение в 1,5 В, то считается, что было передано значение логического нуля. Но если будет передано 5 В, то в соответствующую ячейку памяти будет записана единица. При этом необходимо добиться согласования источника информации с каналом связи. Вообще, при создании электроники необходимо учитывать большое количество различных моментов. Это и энергетические требования, и вид передаваемой информации (дискретная или непрерывная), и многое другое. При этом данные постоянно должны преобразовываться таким образом, чтобы они могли передаваться по каналам связи. Так, в случае с двоичной техникой сигналы представлены в виде напряжения, подаваемого на вход транзисторов или иных компонентов. Во время декодирования данные переводят сообщение в понятный для получателя вид.
Минимальная избыточность
 На практике оказалось, что чрезвычайно важным является, чтобы код сообщения имел минимальную длину. Первоначально может показаться, какая разница – шесть, восемь или шестнадцать бит используется для кодирования? Но различия несущественны, если используется одно слово. А если миллиарды? Благо, можно подстроить алфавитное кодирование под все выдвигаемые требования. Но если про множество ничего неизвестно, то в таком случае сформулировать задачу оптимизации довольно трудно. Но на практике, как правило, всё же можно получить дополнительную информацию. Рассмотрим небольшой пример. Допустим, у нас есть сообщение, представленное на естественном языке. Но оно закодировано, и мы не можем прочитать его. Что нам поможет в задаче расшифровки? Как один из возможных вариантов – листок бумаги, на котором распределена вероятность появления букв. Благодаря этому построение оптимального кода в плане де/кодирования становится возможным с использованием точной математической формулировки и строгого решения.
На практике оказалось, что чрезвычайно важным является, чтобы код сообщения имел минимальную длину. Первоначально может показаться, какая разница – шесть, восемь или шестнадцать бит используется для кодирования? Но различия несущественны, если используется одно слово. А если миллиарды? Благо, можно подстроить алфавитное кодирование под все выдвигаемые требования. Но если про множество ничего неизвестно, то в таком случае сформулировать задачу оптимизации довольно трудно. Но на практике, как правило, всё же можно получить дополнительную информацию. Рассмотрим небольшой пример. Допустим, у нас есть сообщение, представленное на естественном языке. Но оно закодировано, и мы не можем прочитать его. Что нам поможет в задаче расшифровки? Как один из возможных вариантов – листок бумаги, на котором распределена вероятность появления букв. Благодаря этому построение оптимального кода в плане де/кодирования становится возможным с использованием точной математической формулировки и строгого решения.Разбираем пример
Допустим, что у нас есть определённая разделимая схема алфавитного кодирования. Тогда все производные, что представляют собой упорядоченный набор, тоже будет иметь это свойство. При этом если длина элементарных кодов равна, то их перестановка не влияет на длину всего сообщения. Но если размер передаваемой информации напрямую зависит от того, какая последовательность букв, то, значит, были использованы составляющие различной протяженности. При этом, если есть конкретное сообщение и схема его кодирования, то можно подобрать такое решение задачи, когда его длина будет минимальной. Как этого достичь? Давайте рассмотрим подход с использованием алгоритма назначения элементарных кодов, позволяющего результативно подойти к решению задачи эффективности:
- Следует отсортировать буквы в порядке убывания количественного вхождения.
- Нужно разместить элементарные коды в порядке увеличения их длины.
- И как завершение, необходимо разместить составляющие в оптимальном порядке, чтобы наиболее частые символы занимали меньше всего места.
В целом система несложная. Если работать с небольшими объемами данных. Но с современными компьютерами такое реализовать довольно проблематично из-за значительного количества информации.
Заключение
 Вот мы и рассмотрели, что такое система кодирования и декодирования информации, какой она может быть, что сейчас существует в информатике, а также множество иных вопросов. Но всё же следует понимать, что эта тема является чрезвычайно объемной, одной статьи для этого недостаточно. Как продолжение темы можно рассмотреть шифрование данных, криптографию, изменение отображения информации в различной электронике, уровни её обработки и множество других моментов. Но отрасль компьютерных наук по праву считается одной из самых сложных, поэтому изучить всё это быстро не получится. К тому же теоретические знания здесь ой как не равны практическим умениям. А именно последние и обеспечивают качественный результат.
Вот мы и рассмотрели, что такое система кодирования и декодирования информации, какой она может быть, что сейчас существует в информатике, а также множество иных вопросов. Но всё же следует понимать, что эта тема является чрезвычайно объемной, одной статьи для этого недостаточно. Как продолжение темы можно рассмотреть шифрование данных, криптографию, изменение отображения информации в различной электронике, уровни её обработки и множество других моментов. Но отрасль компьютерных наук по праву считается одной из самых сложных, поэтому изучить всё это быстро не получится. К тому же теоретические знания здесь ой как не равны практическим умениям. А именно последние и обеспечивают качественный результат.